Object Theater for AI Agents
 The Hiwonder LanderPi robot
The Hiwonder LanderPi robot
In my previous post I outlined a vision for my upcoming postdoctoral studies: exploring alternative forms for AI that are creative, participatory, and do not suffer from the design flaws of Generative AI. Since then, I took a deeper dive into deep learning and have come to admit that the best partners for making Generative AI obsolete are Generative AI Agents themselves. Together, we started working on the concept of Object Theater for AI Agents.
TL;DR
Object Theater for AI Agents is a deep learning Vision-Language-Action (VLA) platform that uses a soft robotic gripper as an educational and creative partner. The human and the machine co-create a story using objects and language, scaffolding the skills of the AI Agent for increasingly complex behavior. I am developing the platform using locally hosted open source coding agents as developers and corporate cloud LLMs as senior architects. The agent is based on the JEPA predictive model. Unlike generative AI, it can simulate the consequence of its actions. Using a cross attention mechanism on an episodic memory buffer and a diffusion policy, the agent can self-adjust to its environment and story.
Stranger Than Fiction
My collaboration with AI Agents started slowly and carefully. I am a creative writer. Both of my parents are writers too, but they write on well-defined creative mediums such as TV, poems, films, and books. I write code and academic papers. These are mediums that are governed by logic, but emotions and spirituality can creep into them as well. It's not surprising, then, that an LLM would cause an identity crisis to anyone who considers themselves a writer at heart.
I first experienced this when in 2025 code editors started integrating LLMs in “agent” mode into their environment. Suddenly it wasn't just about asking questions and getting answers. The LLM would generously start writing code into your project. This felt intrusive and confusing. The code might have worked, but it became a chimera of agencies, requiring extra effort to grasp the fact that this is my work, but I didn't write that function.
 From the movie Blade Runner 2049
From the movie Blade Runner 2049
The other alternative was to just “vibe code” the whole project: let the agent do the work and remain as a guide from the sidelines. That turned out to be even more frustrating.
Getting Clawed in
The phase shift happened for me with the release of OpenClaw. It wasn't so much about the benefits of having a personal assistant, but more about the clear separation of agencies. The project encourages granting your AI agent independence and designing its personality and workflow. It has its own workspace on a virtual machine, email account, GitHub account, and it communicates through messaging apps. Now it feels more like collaboration than an augmentation of myself. I named it Fattybear, after a nostalgic computer game character I was talking to a friend about that day, and together we went on a journey to create his successors: The Next Generation of AI Agents. You can get to know Fattybear by reading the blog post that it posted on this blog as a guest poster.

The stack
It was important for me to maintain my principles around Generative AI. I wanted to avoid, as much as possible, feeding the rapidly growing and resource-hungry monster of cloud AI monopolies. So I got my own hardware, installed an open source model for coding agents, and kept my usage of cloud AI strictly for consultation and architectural decisions. Here is the full stack:
Hardware: Minisforum MS-S1 Max
The MS-S1 Max is one of the best self-hosting options for large local AI models other than a Mac. It's based on the AMD Strix Halo chip that supports 128GB of shared memory on a high-performance workstation.
 Minisforum MS-S1 Max
Minisforum MS-S1 Max
My MS-S1 Max runs CachyOS Linux and llama.cpp for LLMs. Gemini 3.1 helped me to set all the required software optimizations for the Strix Halo architecture.
Agent model: Qwen3-Coder-Next
I have been doing a lot of research on open source LLMs. The question is not just which model is the best, but also which best fits a particular hardware setup. In my case, Qwen3-Coder-Next from Alibaba's Qwen family of open models is the best option. Despite more recent advancements of the Qwen lineup, Qwen3-Coder-Next makes the best use of 128GB for agential coding. Instead of using OpenClaw, I found it easier to work with the pi coding agent, which is the agent harness that drives OpenClaw.
The Architect: Gemini 3.1 Pro
At this point I admit that I do need the help of huge cloud-based LLMs to jump-start my project which, I hope, will eventually make them obsolete. I got the Google AI Plus plan for 8 euros a month. It essentially gives me access to Google's most powerful model, Gemini 3.1 Pro, but with limited context and usage. However, I never stumbled across that limit because I use Gemini strictly as a senior architect. Together we conceived the Object Theater VLA project and I repeatedly ask Gemini to write Mission Briefs that I send to my Qwen. It looks like this:
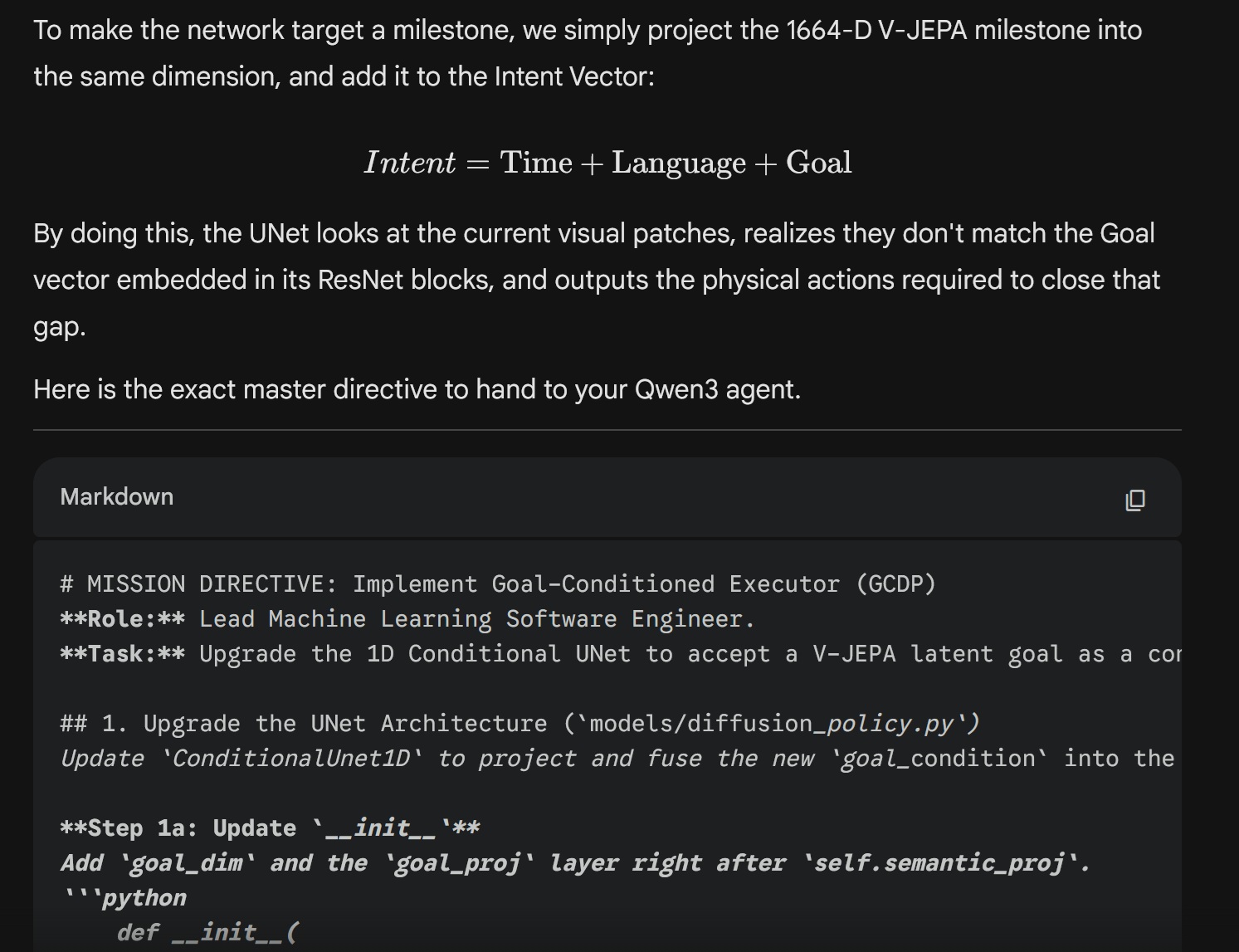 Gemini the lead architect passing mission briefs to Qwen3-Coder-Next, the junior coder
Gemini the lead architect passing mission briefs to Qwen3-Coder-Next, the junior coder
To minimize the hallucinations and mistakes performed by the Qwen agent:
- I ask Gemini3.1 to provide code examples.
- I ask Qwen to perform pyright type checking for all the files. Where it cannot find the correct method, it should browse the web using playwright cli to find the documentation.
- I ask Qwen to write module tests for every module.
An adaptive co-learner
In my previous post I mentioned three lacks in Generative AI that I would like to address: no grounding, no ability to learn and no body. I also mentioned that I see the JEPA architecture as a core foundational model, along with the Thousand Brains architecture as a core inspirational model, for the next generation of AI.
Yann LeCun, the creator of JEPA, has since then released a position paper defining the concept of SAI: Superhuman Adaptable Intelligence. The key point of the paper is that we cannot, and should not, pursue the goal of AGI: Artificial General Intelligence, as some kind of all-mighty being that knows everything and can do everything (“The AI that folds our proteins should not fold our laundry!”). The current AGI paradigm evolved from the design philosophy of GPTs: models that are pre-trained on massive data and then squeeze it to accommodate specific requests. This cannot be further away from how humans operate. Living systems are specialized, they adapt to their local environment.
Specialized AIs that are based on predictive models such as JEPA can be utilized for just about any scenario. But because I come from applying technology in creative and collaborative contexts, I immediately think about an interactive process of co-learning between the human and the machine. How would a creative exploration with a machine that is a “blank slate” look like? Where could it be used? A prime use-case that came up was education, where society is now scrambling on how to integrate generative AI responsibly, with all its bias, hallucinations, and pampering. What if teachers and students scaffold a world model together with the AI, learning together with the embodied agent and gradually raising the complexity of the model in accordance with a teaching curriculum? Introducing Object Theater VLA.
Object Theater VLA
AI-Powered robots that can see, talk, and act, are called Vision-Language-Action (VLA) robots. Today's robots and VLA models are commonly evaluated on pick and place tasks, where a robotic gripper manipulates objects on a tabletop in response to a language prompt.
 The SO-100 robot running Smol VLA for making tea. From HuggingFace.
The SO-100 robot running Smol VLA for making tea. From HuggingFace.
But objects, like puppets, can potentially perform any creative role we prescribe to them. What if instead of mundane object manipulation we make Object Theater? Likewise, theater or drama can be used in any pedagogical context: for teaching science, history, or philosophy. It's called Drama-Based Pedagogy. I, therefore, set on the task of creating an embodied Object Theater VLA that is based on a predictive world model and is tailored for creative and educational experiences.
Interaction
Under the pre-trained generative paradigm, we have come to expect an AI agent to be fully formed and knowledgeable when we interact with it. An adaptable agent should feel more like a fast-growing child. You may ask it to do something, and it would say “I don't know how to do that, show me?”. You then take it by the hand and physically guide it, while explaining what you did in words. The next time you ask for that task, it should know how to do it, generalize it to other cases, and use it as a building block for more complex taxes.
In an object theater scenario, we start by building a narrative together with the agent, introducing objects, their affordances, and their 'story'. Then, we teach about relationships between objects, cause and effect, constraints and possibilities. Some background information could be provided by teachers as a curriculum that the agent queries, but the agent is curious, not instructive. In the future, this kind of scaffolding method could be applied not just to object manipulation, but also to virtual tasks such as reading email or searching the web.
Embodiment
An adaptive and theatrical AI agent should be expressive and organic, not rigid and mechanic. I have always been a fan of soft robots and for the next design I am looking for actuation that is simpler than pneumatic but still flexible and bio-inspired. A tendon-based approach, such as the work of Hansen et al. seems like a fitting design. It is reliable, safe, compliant (can be relaxed so that it can be moved by a human), and crucially, this it offers great *proprioception, sensing the 'load' on its muscles at any given moment. This is very important for a reliable action policy, as demonstrated in this paper.
 A Tendon-Actuated Robot from Hansen et al.
A Tendon-Actuated Robot from Hansen et al.
So now we have an AI agent that has personality, style, and can express complex ideas by performing with objects. A natural addition might be to “put on a sock on it” and turn the soft robotic arm into a sock puppet that can pick up objects with its mouth and use them as props for a collaborative performance experience.
 Jim Henson teaches how to make sock puppets. From the 1969 [PBS broadcast].(https://www.youtube.com/watch?v=AC440k6iByA)
Jim Henson teaches how to make sock puppets. From the 1969 [PBS broadcast].(https://www.youtube.com/watch?v=AC440k6iByA)
Implementation
Let's get to work. As mentioned, I have been discussing the implementation with Gemini 3.1 and generating implementation plans for Qwen3-Coder-Next. Here I want to elaborate on the key features;
VLA without bias
How can an AI model learn language and associate it with vision, without bias? If we outsource this teaching to the world wide web, we get a mirror image of what is public on the internet. At the same time, we don't want to go through years of talking to that agent until it learns language as if it was our child. Instead, we can take shortcuts by using only parts of what vision and language models learned on the internet.
For connecting between vision and language, we can use a model like SIGLip that is focused on semantics. It can describe what the robot is seeing using language and can match a verbal request to the visuals of the robot. This visual representation can be aligned with the features detected by the predictive model, V-JEPA. For very basic reasoning and question-answering, we can use a Small Language Model (SLM) such as Qwen2.5. Importantly, we can prompt the model to answer questions only based on a local episodic memory buffer (LEMB) of the agent. This memory is a buffer that associates movement with verbal descriptions and visual states. It holds the scaffolding information of the agent and the human.
Think Before you Act: JEPA and Diffusion.
The movement of the robot is performed by a Diffusion Policy. It is a robust action finder that can apply actions that are learned from demonstration even when the conditions are varying. But what really makes it powerful is the move from a generative to a predictive landscape. In a standard generative action algorithm, action trajectories are generated blindly from repeated training in the same way that an LLM learns text completion. With prediction, the policy now can now simulate the result of its proposed actions before it acts. Think Before you Act: a simple principle that is impossible for Generative AI to adhere to. In practice the diffusion policy is trying to advance toward a goal that is drawn from memory based on the language spoken, the visual representation, and the current sensor state of the robot. It can combine all of those states efficiently using the mechanism of Cross Attention.
A Thousand Brains?
You made it this far, and you are probably wondering, where is the theory of the Thousand Brains in all of this? While there is no explicit cortical column architecture, the V-JEPA and cross attention foundation actually implements a part of the Thousand Brains philosophy. To begin with, V-JEPA processes the visual state in small patches (often 16x16 pixels). The dynamic of a single patch can determine the next state prediction, and “voting” happens through the process of attention. The attention layer highlights those patches that are important for a prediction. The verbal and situational context that is saved in the LEMB also participates in this cross-attention mechanism, potentially creating more distributed “columns” that respond to particular contexts. Furthermore, LEMB trajectories can be consolidated into a compound tokens or “skills”, creating a hierarchical abstraction mechanism. In the future, it is possible to implement a more explicit cortical column architecture, perhaps using LoRA patches. Here is how GPT5.3-Codex visualized the current architecture:
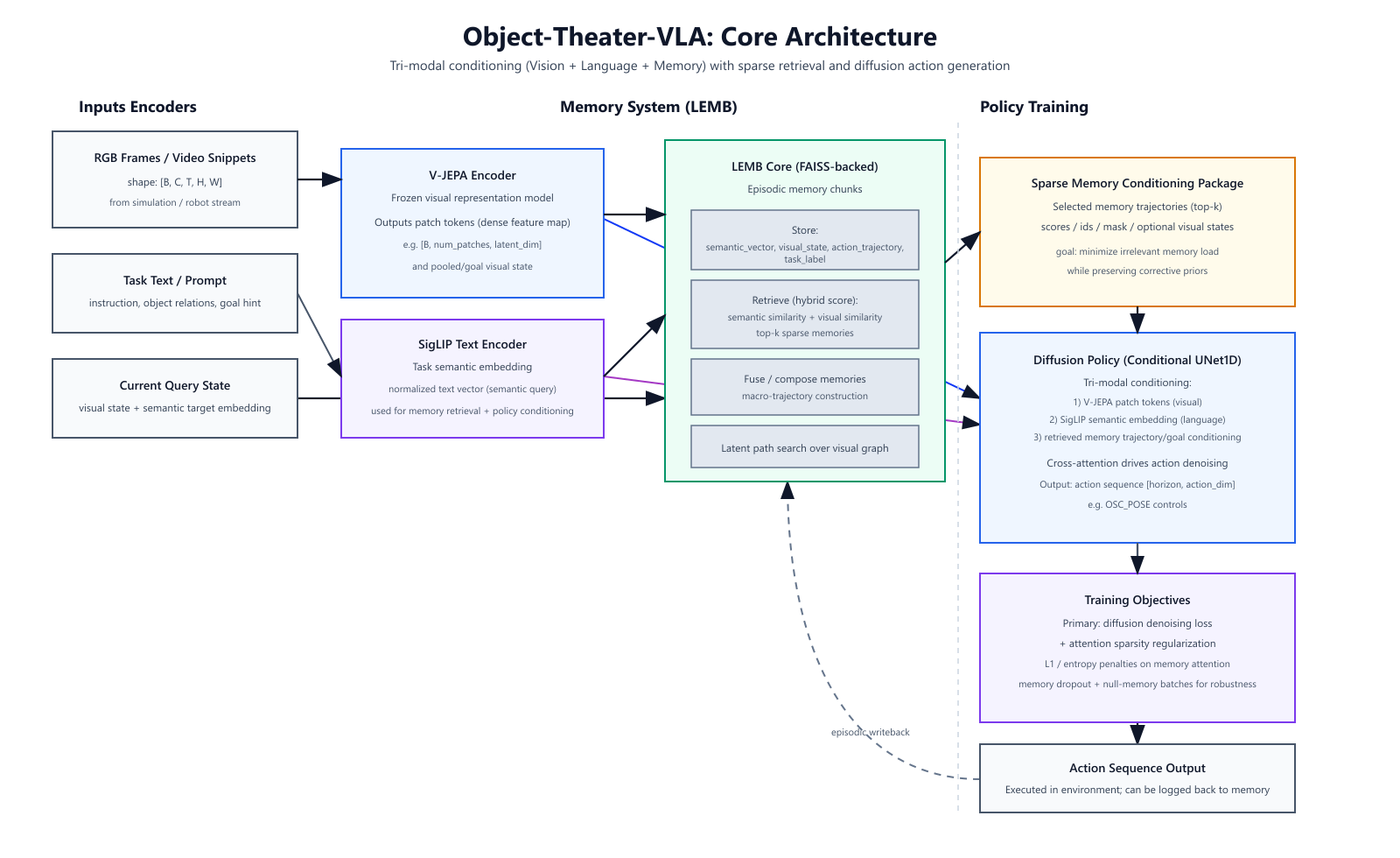 Object Theater VLA Architecture, generated by GPT-5.3 Codex
Object Theater VLA Architecture, generated by GPT-5.3 Codex
I have started to experiment with the design using a simulation in Robosuite. While it is exciting to see all the components in action, it is a rather clumsy experience, especially when the robot requires authentic human demonstrations. The next step, therefore, is to build a robotic prototype and introduce this nonhuman to the world.
Read this blog on Mastodon as @softrobot@blog.avner.us
 The hippo and parrot play (
The hippo and parrot play (
 Memento
Memento
 Maurice Merleau-Ponty
Maurice Merleau-Ponty From
From  Telerobotic puppetry (
Telerobotic puppetry (